How to design infrastructure architecture in AWS Cloud?
From this blog post, you’ll learn about our infrastructure design principles and best practices for architecture based on AWS Cloud.
It’ll show you the basic principles we follow as well as some reference architectures we base on while starting new projects. When you start working with us, we’ll probably bootstrap your project starting from one of the suggested architectures and then build upon that. This approach will give you the best value in time, as we’ll be able to show you the first versions of the product after the first sprint!
AWS accounts structure
For each project, we prefer to start with a new account structure – it gives us the ability to work faster and also better control costs for the projects during the whole project lifecycle.
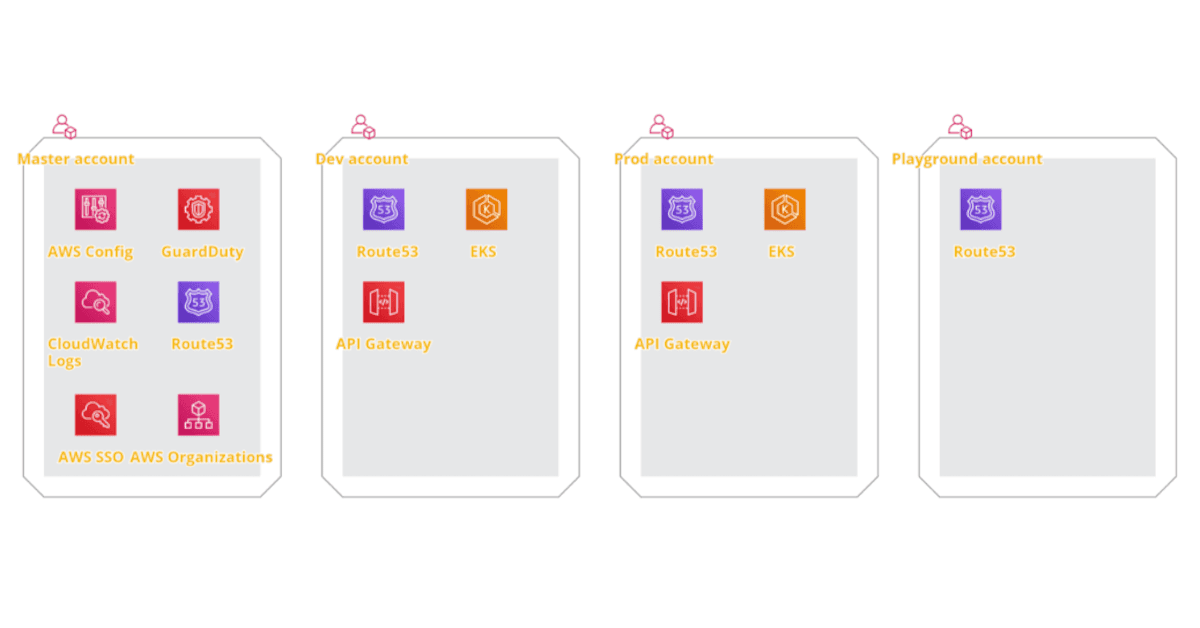
We use AWS Organizations to create accounts structure and AWS SSO to enable secure and efficient access to the accounts.
Usually, we start with Master Account, which holds central services like AWS Organizations and AWS SSO as well as security-related features – aggregated logs, GuardDuty notifications, and AWS Config rules.
Then we create a separate account for each environment like Dev, UAT, and Prod. It increases security by means of isolation. Sometimes, when we need to develop something unusual, we create a Playground account for testing that gets “nuked” after the tests, and it’s the only account we allow not to follow infrastructure-as-a-code approach – even for Dev account we follow full IaaC approach.
All environment accounts are very similar in their configuration – the structure and services used are the same, but for non-production environments, we don’t enable HA and choose smaller instances to save the costs.
Kubernetes-based architecture
For all applications that use state or require to run constantly, we use our Kubernetes cluster architecture. The architecture is presented in the image below.
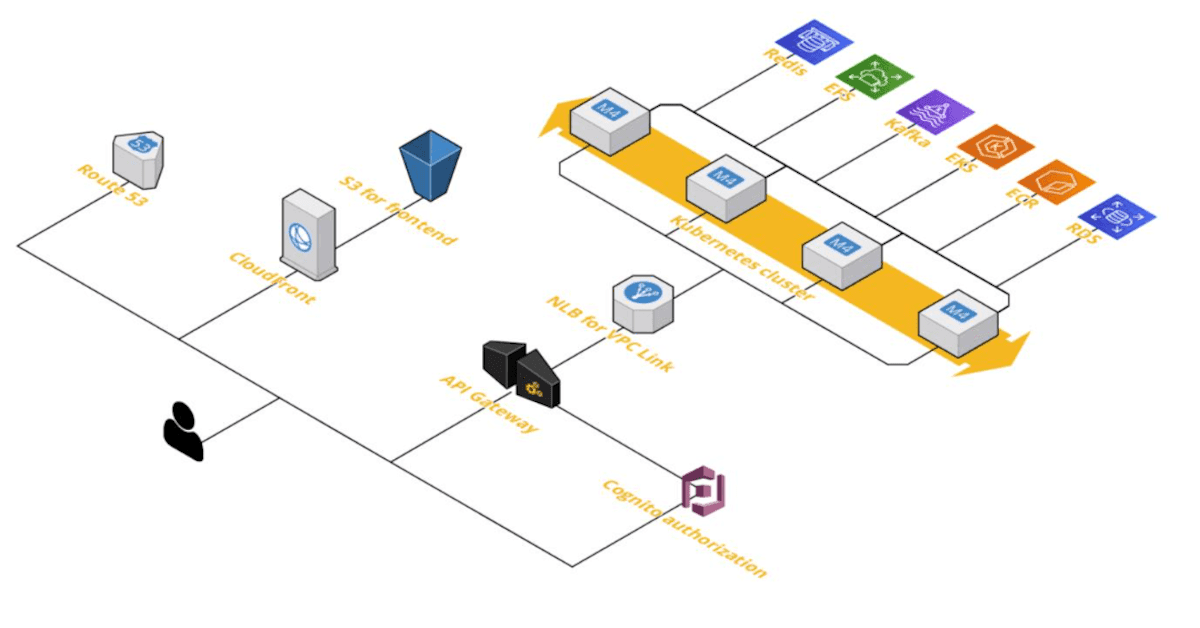
End-user interacts with our infrastructure, starting from Route53 to get IP addresses for our services. Next, the user contacts CloudFront to get an optimized, cached frontend website. We use a single-page approach for our frontend apps, so they don’t need any server rendering and can be delivered in an efficient way to the user.
Our frontend applications contact backend API using API Gateway, which not only caches some responses but also provides throttling and authentication and authorization of the requests. We usually use
Cognito for user identity management.
For secure ingress traffic, we use VPC Link from API Gateway to NLB; then, the traffic gets into the Kubernetes cluster. The cluster itself is configured to be highly available and can auto-scale depending on the load. Depending on the case, applications in the cluster contact multiple backend services such as Redis, Kafka, or RDS.
Serverless architecture
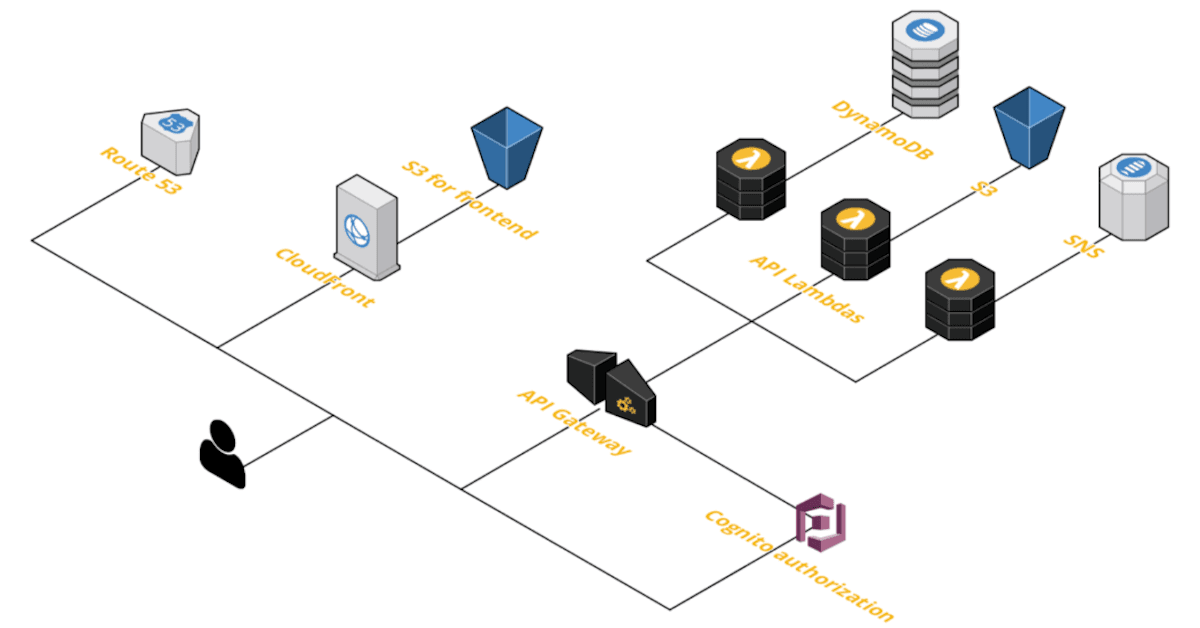
Every time the project doesn’t require stateful services, we suggest going with serverless architecture to provide better OPEX than stateful services. Serverless architecture is very similar to our Kubernetes-based architecture from the user-facing side; the changes are in the backend where we use API Lambdas and sometimes ECS Fargate. In that approach, we also use event-based communication patterns based on SNS as well as serverless data storage such as DynamoDB or S3. It results in cost-efficient, highly scalable infrastructure.
Definition of Done, guidelines, and methodology
Pragmatic Coders embraces a full Continuous Delivery approach where all of the business scenarios are covered by automated tests. In practice, the application code is:
- Reviewed by another developer
- Covered in unit tests, integration tests and system tests when appropriate
- Deployed to dev environment where it’s tested automatically
- Tested manually by team members if necessary
- Pushed to UAT / STAGE / PROD environments in an automated manner via CI / CD
Furthermore, the documentation is up-to-date. Finally, it means that the live deployment was successful, and all of the metrics are green (live production monitoring).
DevOps & Security guidelines
At Pragmatic Coders, we embrace a full shared approach to security promoted by AWS combined with Defence in Depth methodology.
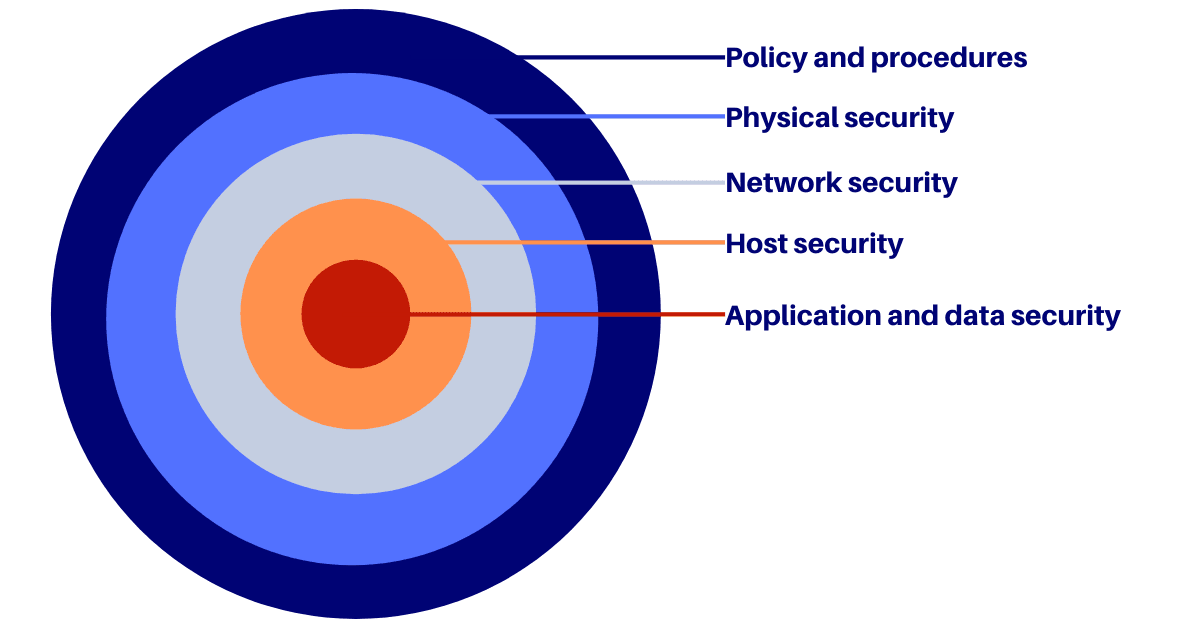
In practice, we:
- Use encryption at rest for all resources that support that.
- Enforce encryption on traffic on all untrusted channels to protect data in transit.
- Use network segmentation to provide isolation between application layers.
- Test the security of our systems with external pentesting companies.
- Ship logs from our apps and systems to a central place to improve auditing and protect them from a deletion in case of a security breach.
- Use long, complex passwords with automatic rotation and wherever possible depend on passwordless (identity-based) authentication such as IAM authentication.
- Follow basic security principles as Defense in Depth, least privilege principle.
- Use secure VPN tunnels for accessing cloud infrastructure.
- Store all secrets in secure locations such as Hashicorp Vault or AWS Secrets Manager.
- Use central identity management systems such as Active Directory or AWS SSO for user authentication, authorization and lifecycle management.
- Use infrastructure-as-a-code approach, so every change in the infrastructure is auditable and reversible.
- Follow GitOps approach, so the infrastructure reflects the code all the time.
- Automate repeatable tasks when it makes sense, to save the time, money and has reliable and repeatable processes.
- Prefer to use high-level tools like Ansible, so the processes we automate are also easy to read by humans.
- Monitor our infrastructure and have alerting in place to be able to quickly react and recover the services as well as prevent failure with predictive alerting.
Design with security in mind
The isolation that AWS Organization provides is the foundation of the security we implement. Each account is isolated, so even if someone gets access, e.g., to the dev environment, that person can’t escalate the attack to the production environment.
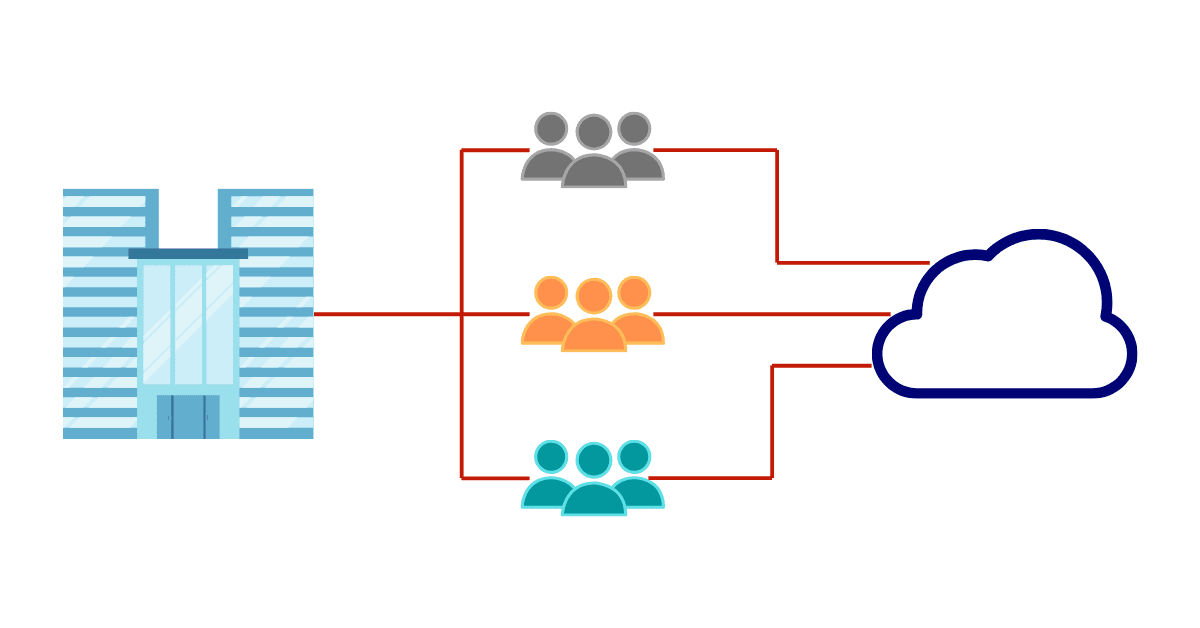
As a rule, we don’t create any IAM users on the accounts for applications; this way, we limit the risk of credentials leakage. We implement AWS Single Sign-On service for every customer, so it’s easy to centrally manage permissions for the access to each AWS account and other applications we deploy to the infrastructure. Having centralized identity management for all developers and administrators gives excellent control over the lifecycle of people working on the infrastructure as well as precise permissions control.
CI/CD pipelines
For things like CI/CD pipelines, we implement either IAM users on the master account and use assume role feature or – in case runners run on the infrastructure – we use instance profiles to provide an identity for the CI/CD.
It’s worth to mention that our CI/CD pipelines are divided into to separate kinds. The first one is meant to be used by developers; it’s constrained and only allows them to take actions necessary to deploy a new version of the application and apply database migrations. The second kind of pipelines is meant to be used by infrastructure provisioning tools. As these pipelines have higher security permissions, we separate them into another group in GitLab CI, so developers can’t make any change in the infrastructure without prior review and acceptance.
Encryption
Regarding encryption at rest, if the customer requires, we implement central management of the KMS key on the master account. This way, we limit the usage of the key outside of the scope of the account that uses it. By doing that, we protect data at rest even if someone gets undesirable administrator access to the account.
Summary. Infrastructure design principles for AWS architecture
Pragmatic Coders is a place where we focus on creating business value and building outstanding software products in a pragmatic and lean way. Leverage our experience in developing cloud-based banking solutions that are optimized for cost and performance efficiency and prepared for scaling.




